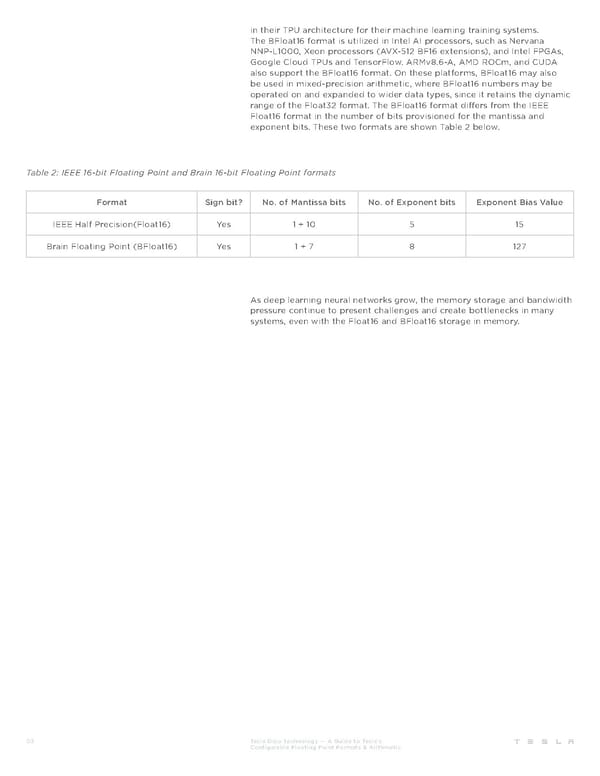
in their TPU architecture for their machine learning training systems. The BFloat16 format is utilized in Intel AI processors, such as Nervana NNP-L1000, Xeon processors (AVX-512 BF16 extensions), and Intel FPGAs, Google Cloud TPUs and TensorFlow. ARMv8.6-A, AMD ROCm, and CUDA also support the BFloat16 format. On these platforms, BFloat16 may also be used in mixed-precision arithmetic, where BFloat16 numbers may be operated on and expanded to wider data types, since it retains the dynamic range of the Float32 format. The BFloat16 format differs from the IEEE Float16 format in the number of bits provisioned for the mantissa and exponent bits. These two formats are shown Table 2 below. Table 2: IEEE 16-bit Floating Point and Brain 16-bit Floating Point formats Format Sign bit? No. of Mantissa bits No. of Exponent bits Exponent Bias Value IEEE Half Precision(Float16) Yes 1 + 10 5 15 Brain Floating Point (BFloat16) Yes 1 + 7 8 127 As deep learning neural networks grow, the memory storage and bandwidth pressure continue to present challenges and create bottlenecks in many systems, even with the Float16 and BFloat16 storage in memory. 03 Tesla Dojo Technology — A Guide to Tesla’s Configurable Floating Point Formats & Arithmetic
 Tesla Dojo Technology Page 2 Page 4
Tesla Dojo Technology Page 2 Page 4